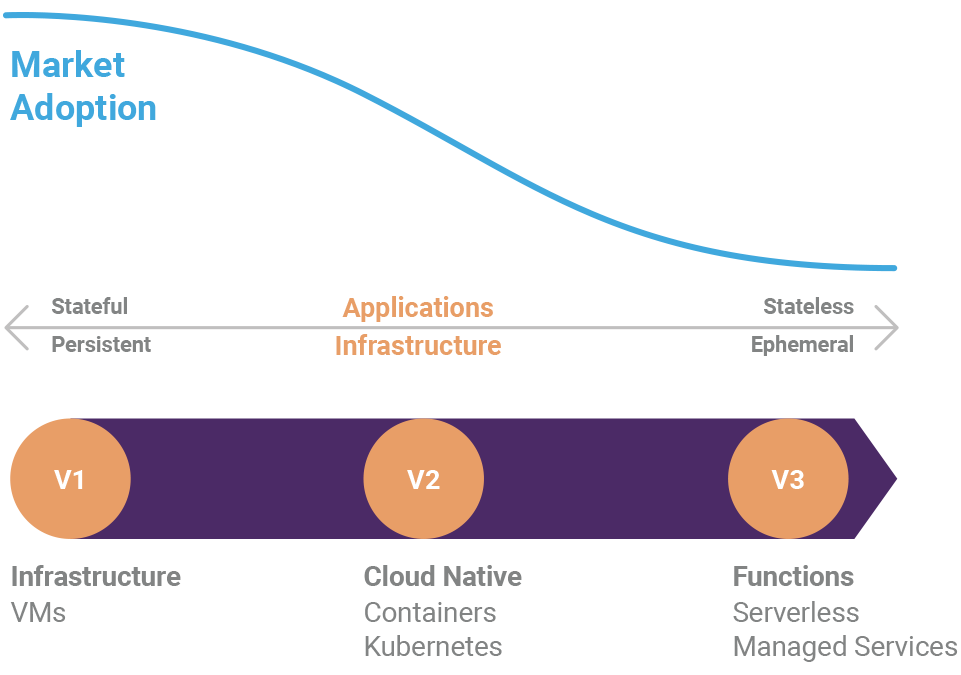
Serverless on AWS with Pulumi: Simple, Event-based Functions

One of Pulumi’s goals is to provide the simplest way possible to do serverless programming on AWS by enabling you to create cloud infrastructure with familiar programming languages that you are already using today. We believe that the existing constructs already present in these languages, like flow control, inheritance, composition, and so on, provide the right abstractions to effectively build up infrastructure in a simple and familiar way.
In a previous post we focused on how Pulumi could allow you to simply create an AWS Lambda out of your own JavaScript function. While this was much easier than having to manually create a Lambda Deployment Package yourself, it could still be overly complex to integrate these Lambdas into complete serverless application.