published on Thursday, Jul 23, 2026 by Pulumi
Serverless App to Copy and Zip Objects Between Amazon S3 Buckets

published on Thursday, Jul 23, 2026 by Pulumi

This example sets up two AWS S3 Buckets and a single Lambda that listens to one and, upon each new object arriving in it, zips it up and copies it to the second bucket. Its architecture looks like this:
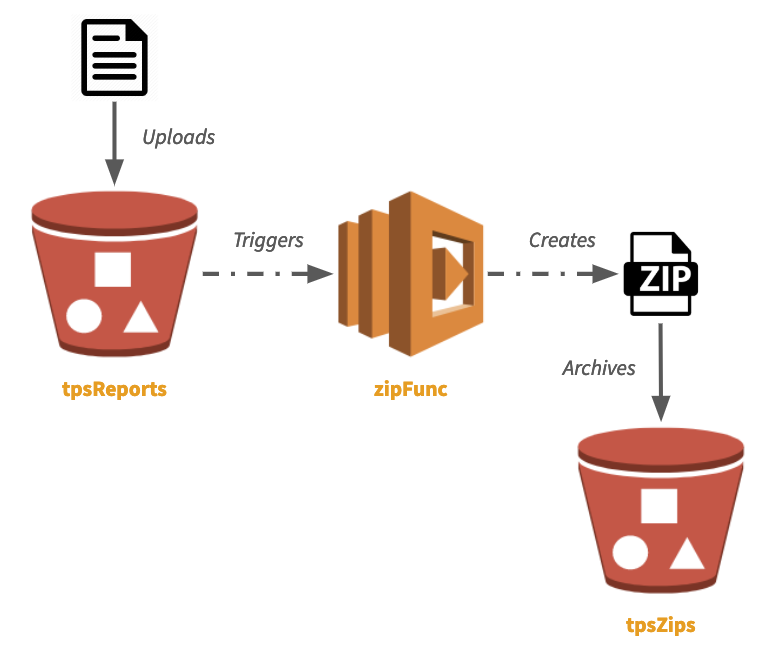
This example is also featured in the blog post Easy Serverless Apps and Infrastructure – Real Events, Real Code.
Deploying the App
To deploy your new serverless application, follow the below steps.
Prerequisites
Steps
After cloning this repo, from this working directory, run these commands:
Install Node.js dependencies, either using NPM or Yarn:
$ npm installCreate a new Pulumi stack, which is an isolated environment for this example:
$ pulumi stack initThis will ask you to give your stack a name;
devis a fine name to begin with.Configure the AWS region for this program – any valid AWS region will do:
$ pulumi config set aws:region us-east-1Deploy the application:
$ pulumi upAfter about 20 seconds, your buckets and lambda will have been deployed. Their names are printed:
Outputs: tpsReportsBucket: "tpsreports-21b7b7a" tpsZipsBucket : "tpszips-c869600"Now copy a file to the
tpsReportsBucketusing the AWS CLI:$ aws s3 cp ./myTpsReport001.txt s3://$(pulumi stack output tpsReportsBucket)Tail the logs to see evidence the Lambda ran:
$ pulumi logs -f Collecting logs for stack dev since 2019-03-10T10:09:56.000-07:00... 2019-03-10T11:10:48.617-07:00[zipTpsReports] Zipping tpsreports-96458ef/tps001.txt into tpszips-edfde11/tps001.txt.zip^C out of
pulumi logs -f, and then download your new zipfile!$ aws s3 cp s3://$(pulumi stack output tpsZipsBucket)/myTpsReport001.txt.zip .Once you’re done, destroy your stack and remove it – eliminating all traces of running:
# First, delete files so we can destroy the buckets (by default, bucket content isn't auto-deleted): $ aws s3 rm s3://$(pulumi stack output tpsReportsBucket)/myTpsReport001.txt $ aws s3 rm s3://$(pulumi stack output tpsZipsBucket)/myTpsReport001.txt.zip $ pulumi destroy --yes $ pulumi stack rm --yes
published on Thursday, Jul 23, 2026 by Pulumi