published on Tuesday, Jun 16, 2026 by Pulumi
Serverless Datawarehouse

published on Tuesday, Jun 16, 2026 by Pulumi

A sample project that deploys a serverless data warehouse. This highly scalable data warehouse is pay as you go, scales read and write workload independently, and uses fully managed services.
Deploy and run the program
- Create a new stack
pulumi stack init dev
- Install dependencies
npm install
- Deploy
pulumi up
- Open Athena in the AWS Console, and perform some queries:
select * from analytics_dw.clicks;
- Clean up the stack
pulumi destroy
Testing
Unit Tests
npm run test:unit
Integration Tests
There is an integration test that deploys a fresh stack, ingests sample data, and verifies that the data can be queried on the other end through Athena.
Because ServerlessDataWarehouse statically names Glue Databases, the integration test will fail with a 409 conflict if you already have a dev stack running.
# make sure you have run a pulumi destroy against your dev stack first
npm run test:int
API
ServerlessDataWarehouse: class
A container for your data warehouse that creates and manages a Glue Database, an S3 Bucket to store data, and another S3 bucket for Athena query results.
Constructor
ServerlessDataWarehouse(name: string, args?: DataWarehouseArgs, opts?: pulumi.ComponentResourceOptions)
Parameters:
name: string: Name of the Pulumi resource. Will also be used for the Glue Database.args: DataWarehouseArgs:database?: aws.glue.CatalogDatabase: optionally provide an existing Glue Database.isDev?: boolean: flag for development, enables force destroy on S3 buckets to simplify stack teardown.
const dataWarehouse = new ServerlessDataWarehouse("analytics_dw");
// make available as pulumi stack output
export dwBucket = dataWarehouse.dataWarehouseBucket;
Members:
dataWarehouseBucket: aws.s3.bucket: Bucket to store table data.queryResultsBucket: aws.s3.Bucket: Bucket used by Athena for query output.database: aws.glue.CatalogDatabase: Glue Database to hold all tables created through method calls.
Methods:
withTable: function
Creats a glue table owned by creates a Glue Table owned by this.database configured to read data from ${this.dataWarehouseBucket}/${name}
Parameters:
name: string: The name of the table. The table will be configured to read data from${this.dataWarehouseBucket}/${name}.args: TableArgs:columns: input.glue.CatalogTableStorageDescriptorColumn[]: Description of the schema.partitionKeys?: input.glue.CatalogTablePartitionKey[]: Partition keys to be associated with the schema.dataFormat?: "JSON" | "parquet": Specifies the encoding of files written to${this.dataWarehouseBucket}/${name}. Defaults to parquet. Will be used to configure serializers and metadata that enable Athena and other engines to execute queries.
const factTableName = "facts";
const factColumns = [
{
name: "thing",
type: "string"
},
{
name: "color",
type: "string"
}
];
const factTableArgs: TableArgs = {
columns: factColumns,
dataFormat: "JSON"
};
dataWarehouse.withTable("facts", factTableArgs);
withStreamingBatchInputTable: function
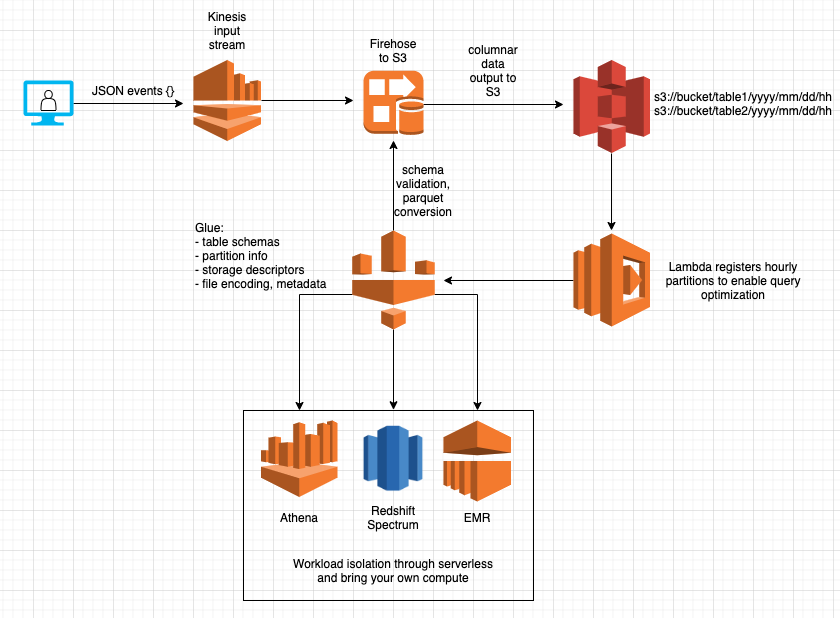
Creates a table implements the above architecture diagram. It creates a Kinesis input stream for JSON records, a Glue Table, and Kinesis Firehose that vets JSON records against the schema, converts them to parquet, and writes files into hourly folders ${dataWarehouseBucket}/${tableName}/YYYY/MM/DD/HH. Partitions are automatically registered for a key inserted_at="YYYY/MM/DD/HH to enable processing time queries.
Parameters:
name: string: The name of the table. The table will be configured to read data from${this.dataWarehouseBucket}/${name}.args: StreamingInputTableArgscolumns: input.glue.CatalogTableStorageDescriptorColumn[]: Description of the schema.inputStreamShardCount: number: Number of shards to provision for the input Kinesis steam. This is how you scale your write workload.region: string: region to localize resources like Kinesis and LambdapartitionKeyName?: string: Name of theYYYY/MM/DD/HHpartition key. Defaulst toinserted_at.partitionScheduleExpression?: stringAWS Lambda cron expression used to schedule the job that writes partition keys to Glue. Defaults torate(1 hour). Useful for development or integration testing where you want to ensure that partitions are writtin in a timely manner.
fileFlushIntervalSeconds?: number: Period in seconds that Kinesis shards flush files to S3. Defaults to the max of 900 (15 minutes). Min 60 seconds.
const columns = [
{
name: "id",
type: "string"
},
{
name: "session_id",
type: "string"
},
{
name: "event_time",
type: "string"
}
];
const impressionsTableName = "impressions";
const streamingTableArgs: StreamingInputTableArgs = {
columns,
inputStreamShardCount: 1,
region: "us-west-2",
partitionScheduleExpression: "rate(1 minute)",
fileFlushIntervalSeconds: 60
};
const dataWarehouse = new ServerlessDataWarehouse("analytics_dw", { isDev })
.withStreamingInputTable("impressions", streamingTableArgs);
withBatchInputTable: function
Designed for batch loading tables on a regular cadence. Creates a Glue Table and executes the user specified function on the specified interval. Function runs inside of Lambda, and must be able to operate within the Lambda runtime constraints on memory, disk, and execution time. Runs with 3GB RAM, 500MB disk, and 15 min timeout.
Parameters:
name: string: The name of the table. The table will be configured to read data from${this.dataWarehouseBucket}/${name}.args: BatchInputTableArgs:columns: input.glue.CatalogTableStorageDescriptorColumn[]: Description of the schema.partitionKeys?: input.glue.CatalogTablePartitionKey[]: Partition keys to be associated with the schema.jobFn: (event: EventRuleEvent) => any: Code to be executed in the lambda that will write data to${this.dataWarehouseBucket}/${name}.scheduleExpression: string: AWS Lambda cron expression thatjobFnwill execute on.policyARNsToAttach?: pulumi.Input<ARN>[]: List of ARNs needed by the Lambda role forjobFnto run successfully. (Athena access, S3 access, Glue access, etc).dataFormat?: "JSON" | "parquet": Specifies the encoding of files written to${this.dataWarehouseBucket}/${name}. Defaults to parquet. Will be used to configure serializers and metadata that enable Athena and other engines to execute queries.
const aggregateTableName = "aggregates";
const aggregateTableColumns = [
{
name: "event_type",
type: "string"
},
{
name: "count",
type: "int"
},
{
name: "time",
type: "string"
}
];
// Function reads from other tables via Athena and writes JSON to S3.
const aggregationFunction = async (event: EventRuleEvent) => {
const athena = require("athena-client");
const bucketUri = `s3://${athenaResultsBucket.get()}`;
const clientConfig = {
bucketUri
};
const awsConfig = {
region
};
const athenaClient = athena.createClient(clientConfig, awsConfig);
let date = moment(event.time);
const partitionKey = date.utc().format("YYYY/MM/DD/HH");
const getAggregateQuery = (table: string) => `select count(*) from ${databaseName.get()}.${table} where inserted_at='${partitionKey}'`;
const clicksPromise = athenaClient.execute(getAggregateQuery(clicksTableName)).toPromise();
const impressionsPromise = athenaClient.execute(getAggregateQuery(impressionsTableName)).toPromise();
const clickRows = await clicksPromise;
const impressionRows = await impressionsPromise;
const clickCount = clickRows.records[0]['_col0'];
const impressionsCount = impressionRows.records[0]['_col0'];
const data = `{ "event_type": "${clicksTableName}", "count": ${clickCount}, "time": "${partitionKey}" }\n{ "event_type": "${impressionsTableName}", "count": ${impressionsCount}, "time": "${partitionKey}"}`;
const s3Client = new S3();
await s3Client.putObject({
Bucket: dwBucket.get(),
Key: `${aggregateTableName}/${partitionKey}/results.json`,
Body: data
}).promise();
};
const policyARNsToAttach: pulumi.Input<ARN>[] = [
aws.iam.ManagedPolicy.AmazonAthenaFullAccess,
aws.iam.ManagedPolicy.AmazonS3FullAccess
];
const aggregateTableArgs: BatchInputTableArgs = {
columns: aggregateTableColumns,
jobFn: aggregationFunction,
scheduleExpression,
policyARNsToAttach,
dataFormat: "JSON",
}
dataWarehouse.withBatchInputTable(aggregateTableName, aggregateTableArgs);
getTable: function
Retrieves a table with the specified name.
Parameters:
name: stringthe name of theServerlessDataWarehouseowned table to retrieve.
listTables: function
Returns an array of table names managed by this data warehouse.
getInputStream: function
Retrieves the input stream associated with the specified table name, if any.
Parameters:
tableName: string: Name of the table to find an associated inputStream for.
published on Tuesday, Jun 16, 2026 by Pulumi