Abstracting Pulumi Code
Just like any application code, Pulumi infrastructure code can be abstracted, enabling us to work with high-level, generic representations of the things we need to build. If we use an object-oriented language such as JavaScript, TypeScript, Python, C#, or Java, we can create and instantiate classes. For languages like Go, we can build up interfaces. In all cases, we’re thinking in terms of taking code that we’ve written and making it reusable in some form. Let’s first explore abstraction.
Thinking in abstraction
When we use our code for our Pulumi program, we’re generally starting out with a very basic case. Perhaps we’re building out a general proof-of-concept, or a one-off architecture for learning purposes. In those cases, keeping all of the code in a single file with no classes, functions, or other structures probably is enough.
To get to more complex architectures, we need the ability to break apart that code so we can reuse components and call things in any order we choose, knowing that we will get the expected result each time. We also need to allow others to use parts of our code without necessarily needing to know precisely how it’s put together. This abstractionist way of thinking means we’re thinking in terms of the mental models we use to understand the cloud architectures that are available to us—or what we want to make available to others in our organization.
Exploring an example
In the last part of this tutorial, we took a simple S3 bucket build and broke out the code into reusable parts. As a build, it’s still dependent on the structures built around an S3 bucket. Let’s imagine the Pulumipus brand is expanding to all kinds of systems, and so we don’t know which infrastructure each team will need. Could we reuse the ideas we just explored? Well, each team will need some kind of storage for objects that has access policies and security controls, no matter whether they’re doing a serverless build or a VM-based build. Believe it or not, that mental model, or that abstraction, is nearly identical to the mental model we just built up for S3 buckets, just without depending on the structures of AWS.
Mentally, we’re defining an abstract cloud storage system like this:
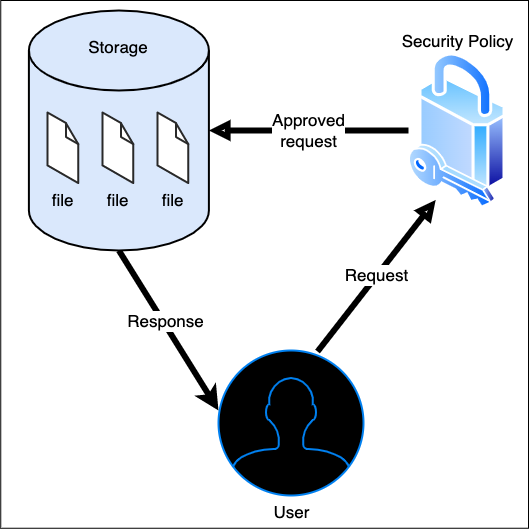
Drawn with draw.io
Seems pretty clean, doesn’t it? Abstraction is thinking through what we experience when we call the code, so that anyone calling that code experiences the same thing. The part that gets complicated is when we start translating that idea to code. To abstract something away, we provide a higher-level interface for someone to use to request that experience overall without needing to know all of the low-level details regarding how that experience is put together, such as which policies are necessary to get the desired result.
With Pulumi, one way to abstract the prior work away to match this diagram a bit better might be to wrap the whole thing in another class that requires you to define which cloud provider you want to use, kind of like this pseudo code layout:
// ...
type SupportedCloud = "aws" | "gcp";
class StorageClass {
constructor(cloud: SupportedCloud) {
switch (cloud) {
case "aws":
// Create AWS storage resources...
break;
case "gcp":
// Create Google Cloud storage resources...
break;
}
}
}
# ...
class StorageClass:
def __init__(self, cloud):
cloud = self.cloud
if cloud is 'aws':
# aws class here
elif cloud is 'gcp:
# gcp class here
elif ...
There’s a cleaner way to do this, though, with Pulumi if you want to start to share these abstractions with others. We call them Component Resources. Let’s go explore them next!
