Superintelligence infrastructure
Infrastructure that orchestrates itself alongside AI workloads. Managed with code, not static configuration.
From pre-training on 100,000+ GPUs to serving billions of inference requests, Pulumi enables infrastructure that adapts as your AI workloads change. Built for ML teams who need to move fast without rewriting infrastructure at every scale.

Proven at massive scale
15,000
developers with self-service access to production-grade infrastructure

< 1 Day
deployment cycles reduced from 1.5 weeks to under 24 hours

80,000+
resources across 16 regions, infrastructure written in the same language as our services

The complete AI infrastructure lifecycle
From research experiments to superintelligence-scale production.
One platform, one codebase, any cloud.
Pre-training
- Distribute training across 100,000+ GPUs
- Manage petabytes of checkpoints
- Orchestrate fault recovery during months-long runs
Self-supervised learning
- Massive training clusters with fault tolerance
- GPU observability at scale
- Adapt to hardware heterogeneity across clouds
Supervised fine-tuning
- Rapid experimentation with LoRA and full fine-tuning
- Launch hundreds of training runs with different datasets
- Track experiments and version datasets
Reinforcement learning
- Orchestrate RLHF and RLAIF pipelines
- Coordinate multiple models: training, reference, reward, LLM judges
- Dynamic infrastructure provisioning for each iteration
Inference
- Auto-scaling GPU clusters serving millions of requests
- Multi-region routing for low latency
- Rolling deployments of new model versions
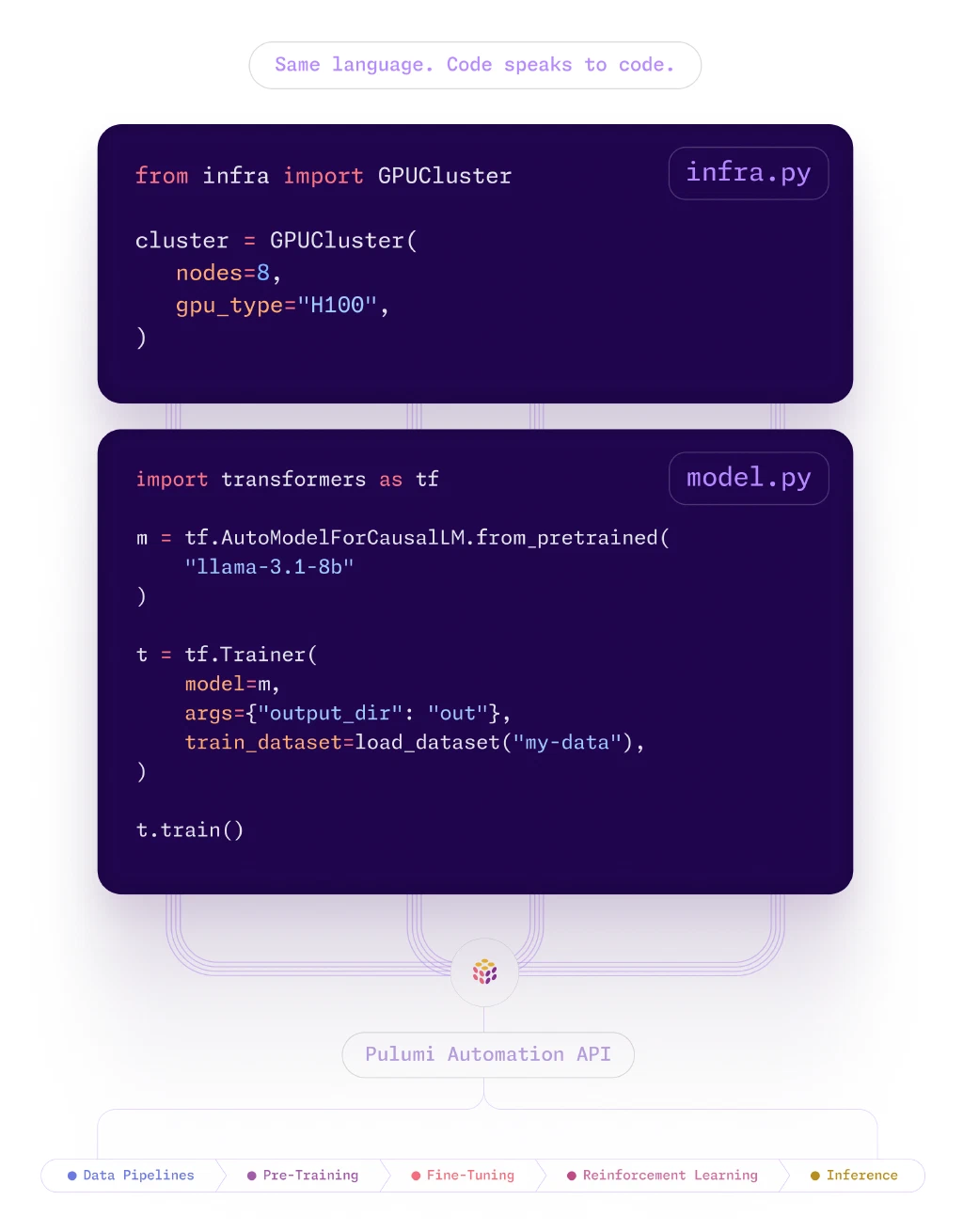
Code-native infrastructure for dynamic AI workloads
Infrastructure written in Python, TypeScript, and Go. The same languages your ML engineers already know.
No proprietary configuration languages.

Trusted for building AI products at massive scale
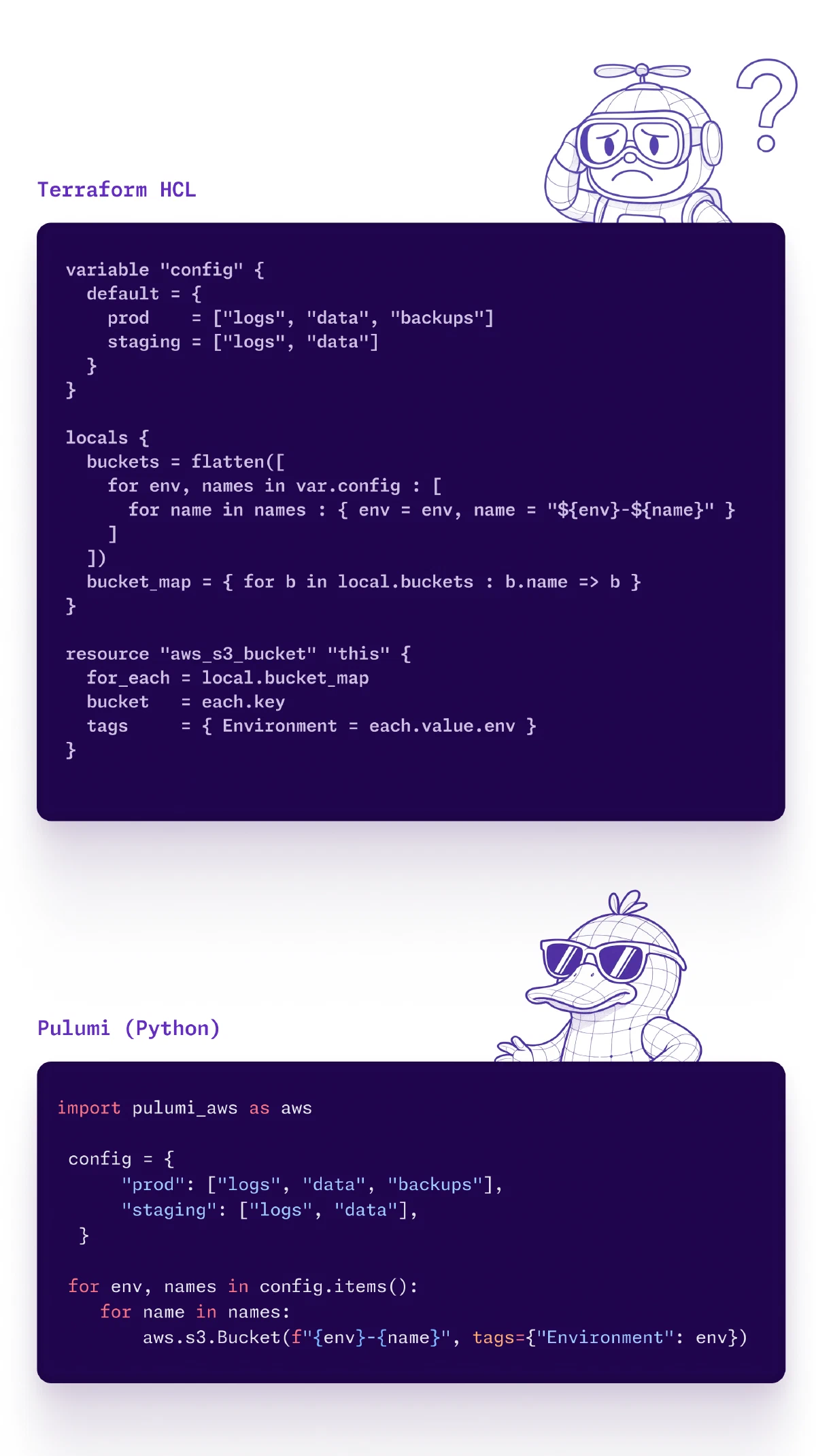
From Terraform’s configuration language to 80K resources in real code
Supabase needed infrastructure that could scale without operational overhead. Terraform’s HCL meant constant context switching between TypeScript (application services) and a proprietary configuration language (infrastructure).
After migrating to Pulumi:
- Regional expansion: 1 week to infrastructure readiness
- Scale: 80,000 resources across 16 AWS regions
- Team velocity: 1-2 people to 40+ active engineers
- Multi-cloud: AWS + Cloudflare + GCP in single deployments
Supabase powers AI application builders like Lovable, Bolt, and Vercel v0: 43,000+ databases launched daily, 100K+ API calls per second. The backend infrastructure runs entirely on Pulumi.
"With Pulumi, everything is TypeScript. Our infrastructure is code, not configuration."
- Paul Cioanca, Platform Engineer at Supabase
Also trusted by leading AI and data platforms
Snowflake manages 100K+ daily deployments across AWS, Azure, and GCP with Pulumi — massive-scale infrastructure supporting AI/ML workloads for thousands of enterprise customers.
BMW enables 15,000 developers to access self-service infrastructure while maintaining enterprise governance.
Code enables AI-managed infrastructure
Your ML models are written in Python. Your infrastructure should be too.
Pulumi’s code-native architecture creates a fundamental advantage: AI systems can read, write, and optimize infrastructure written in Python, TypeScript, or Go. The same languages used to train large language models.
This isn’t AI translating natural language into proprietary configuration syntax. This is AI working directly with production infrastructure code.
Neo: AI-powered infrastructure operations, grounded in reality
Once you’re managing infrastructure with Pulumi, Neo automates the operations that slow development cycles. Neo is grounded in Pulumi’s 2+ petabyte corpus of real production infrastructure deployments. While generic AI tools can hallucinate plausible-sounding configurations, Neo draws on battle-tested patterns from billions of real cloud resources:
- Policy migration converts security policies from Terraform or CloudFormation using patterns that already work in production
- Drift remediation detects and fixes configuration drift in GPU clusters based on how teams actually manage these resources at massive scale
- Multi-cloud migration converts AWS SageMaker infrastructure to Azure ML or GCP Vertex AI using production-ready patterns
The code-native advantage: LLMs are trained on real code, not proprietary configuration languages. Pulumi IS code. This enables fundamentally deeper AI integration than tools that require translation layers.
Why AI infrastructure requires dynamic orchestration
Static configuration languages (Terraform HCL)
- Designed for long-lived resources that change infrequently
- Cannot dynamically rebalance GPU capacity as workloads shift
- Proprietary DSL requires learning syntax separate from application development
- AI tools must translate natural language → DSL → infrastructure (abstraction overhead)
- Limited to configuration-specific operations; can’t leverage full programming language ecosystems
- Testing requires DSL-specific tools and frameworks
Code-native infrastructure (Pulumi)
- Built for AI workloads that require real-time resource reallocation
- Shift capacity between inference and training based on demand
- Python, TypeScript, Go, C#: languages your ML engineers already know
- AI tools work directly with infrastructure code (same languages that train LLMs)
- Full SDLC support: type safety, testing frameworks, package managers, and IDE integration
- Software engineering practices apply directly to infrastructure
Build superintelligence infrastructure in minutes
Get started with Pulumi Cloud
Join Snowflake, Supabase, BMW, and leading AI companies managing production-ready infrastructure at massive scale with code, not static configuration.