

AI coding has two shapes right now. One agent in a loop, sequential work, you babysitting the chat window. Call that 2x. Most teams live here. Five agents in worktrees, parallel work, fresh-context review on every change. Call that 10x. The trick: 2x is mostly prompting, 10x is mostly plumbing.
The parallel coding playbook is a five-pattern setup for running multiple AI coding agents at the same time without them stepping on each other: an issue used as the spec, a plan/build/validate loop, parallel git worktrees, fresh-session review, and a self-healing layer. The whole thing targets application code. The interesting question, and the one I keep ending up at, is what changes when the five agents are touching infrastructure.
2x is prompting, 10x is plumbing
2x is one human, one agent, one repo, one branch. The agent writes, you review, you tell it to try again, it tries again. The bottleneck is your attention. Whatever the agent’s raw throughput, your reading speed sets the ceiling.
10x moves you out of the per-change loop and into the issue loop. You write five issues with sharp acceptance criteria, send each one to its own agent in its own worktree, and let them plan, build, and validate end-to-end. You read five PRs at lunch instead of pair-programming on one all morning.
Concurrent isolation does the work. And isolation is mostly an infrastructure problem.
The five pillars
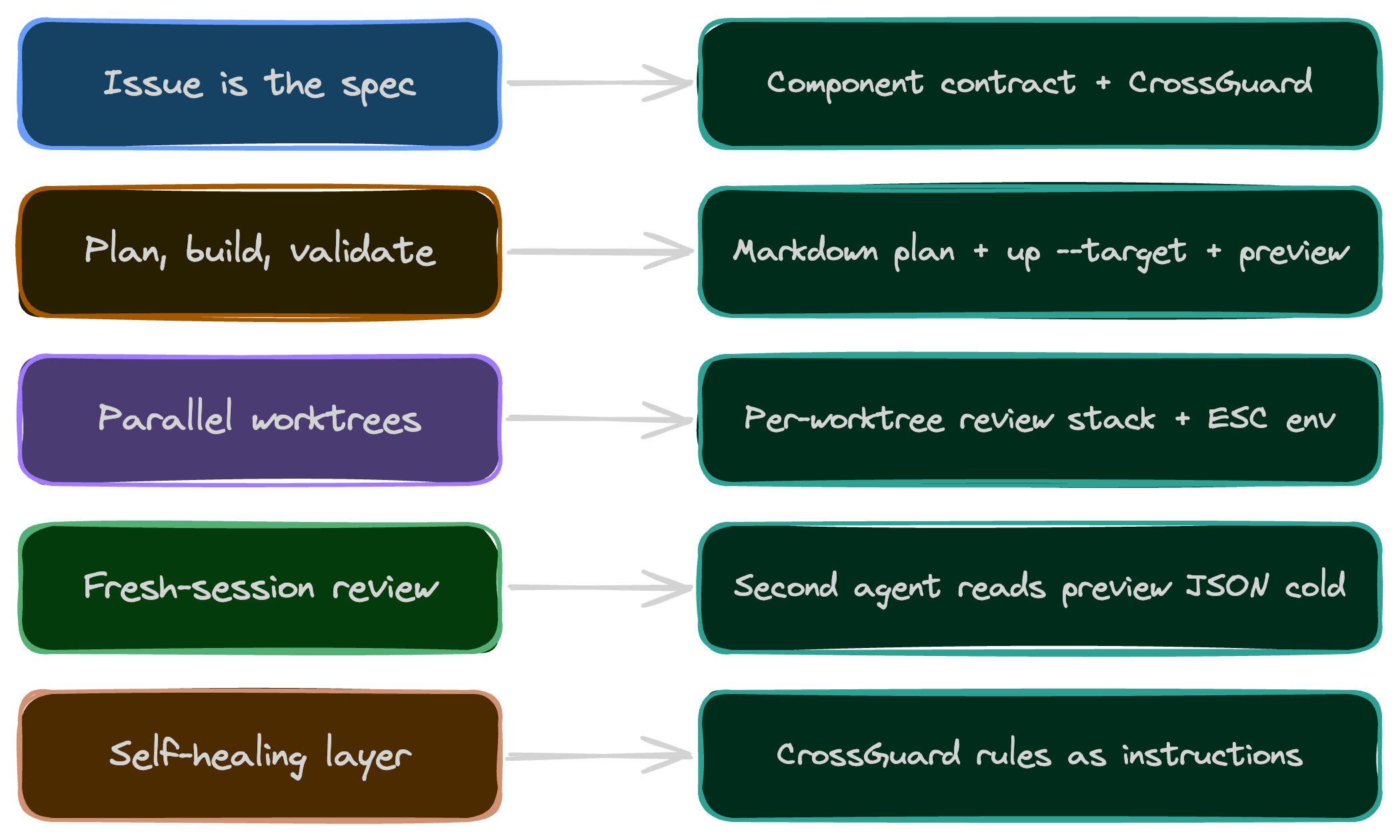
The five pillars, in one sentence each.
- Issue is the spec. The GitHub issue carries the acceptance criteria. The pull request is the artifact that gets validated. Input and output of every implementation are versioned, scoped, and reviewable on their own.
- Plan, build, validate. Three stages, three artifacts. A markdown plan you can read in thirty seconds. A build that produces a diff. A validate step that checks the diff against the spec.
- Parallel worktrees. Each agent runs in its own git worktree so concurrent changes never trample each other. One repo, five working trees, five branches.
- Fresh-session review. A different agent, a different conversation, no shared context, reads the output and judges it. The reviewer never sees the writer’s chat. An agent reviewing its own output in the same context is theater.
- Self-healing layer. When the same issue keeps coming back, fix the system that allowed it. Update the rules, the skills, the
AGENTS.md. The agent gets better; the bug class disappears.
The application-code version of this playbook leans on ports, node_modules, and databases to get isolation right. The infrastructure version has a different toolbox.
What changes when the agents are touching infrastructure
Walk the pillars again, this time with a Pulumi shop in mind.
Issue is the spec. For application code, the spec describes behavior. For infrastructure, the spec is a Pulumi component contract plus a Pulumi Policies excerpt. “The resulting bucket is private, lives in eu-west-1, has SSE-KMS, and is tagged owner=team-x.” That sentence compiles to a typed component signature and three policy assertions. The agent does not get to interpret “looks right.” The acceptance criteria are deterministic, which is the whole reason this works.
Plan, build, validate. Pulumi already ships the validate step. pulumi preview produces a deterministic, machine-readable diff a second reviewer can judge without the conversation that produced it. The plan is a markdown doc the agent writes before touching code. The build is pulumi up --target against a review stack scoped to the resources the issue covers. The validate step is the preview output plus the Pulumi Policies verdict.
Parallel worktrees. Worktrees alone are not enough. Two worktrees pointing at the same Pulumi stack will fight over state on the first concurrent up. The unit of isolation for infrastructure is the stack, not the worktree. Each worktree gets its own ephemeral review stack and its own ESC environment for credentials. State branches with the work, credentials branch with the work, and the cloud account does not see five agents elbowing each other.
Fresh-session review. The hardest part of the application-code version is keeping the reviewer cold. For infrastructure, the substrate hands you the cold context. The pulumi preview JSON has no memory of the prompt that produced it. A separate agent reading it has the same starting point a human reviewer has: a diff, a stack name, a policy report. Pulumi Neo reasons over the state graph directly, so the reviewer grounds every claim in what the change actually does, not what the writer says it does. Reviewer quality still depends on how well your policies cover the stack, but the cold-context part comes built in.
Self-healing layer. Most Pulumi Policies rule messages today read like assertions. “S3 bucket has no encryption.” A self-healing layer needs them to read like instructions. “S3 bucket has no encryption. Set serverSideEncryptionConfiguration with SSE-KMS to fix.” That single rewrite is the difference between an agent flailing and an agent fixing the violation on the first try. When the same rule keeps tripping, the fix is upstream of the next pull request: in the rules, in the skills, in the policy itself.
The five catches, infra edition
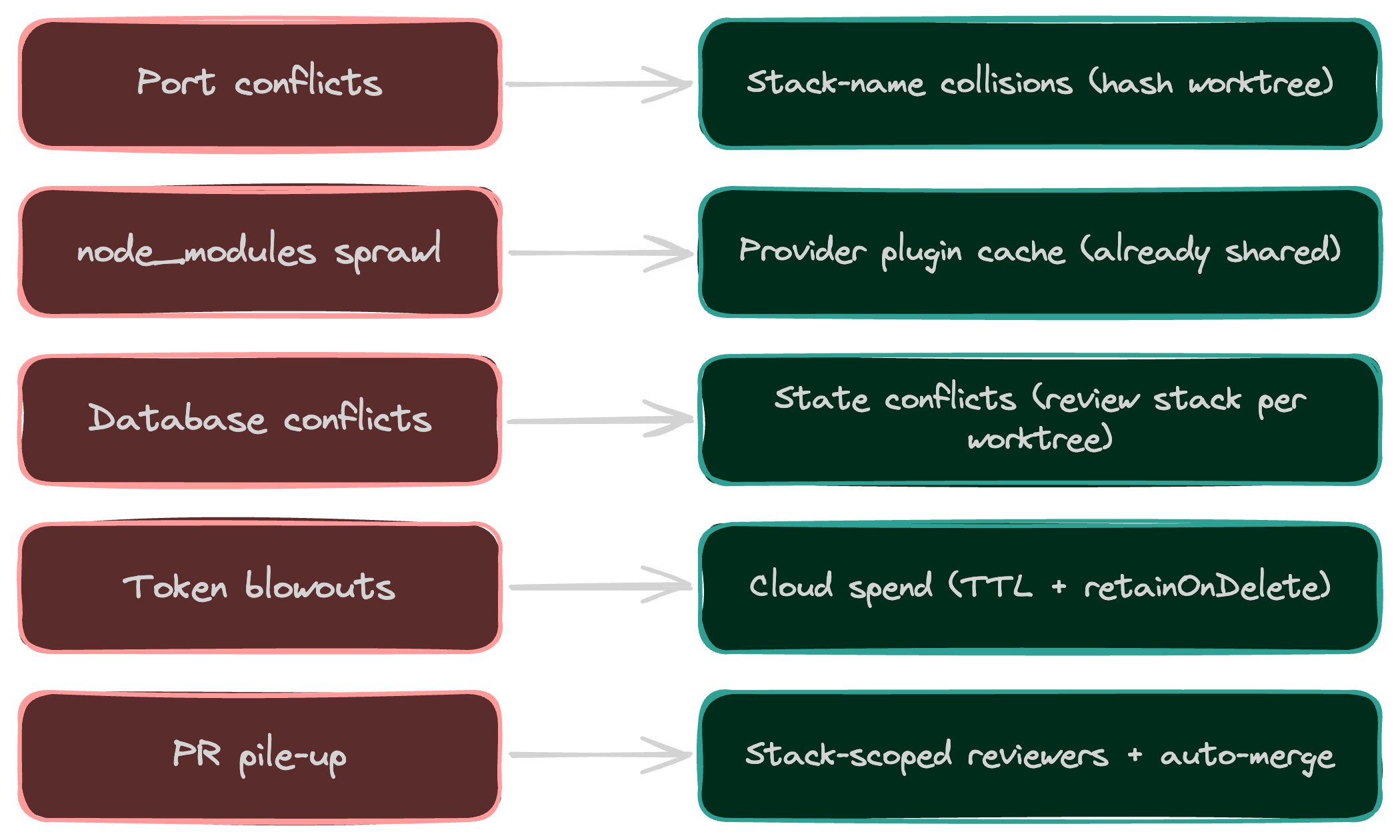
Every parallelism story has a catch list. The application-code version lists port conflicts, node_modules sprawl, database conflicts, token blowouts, and PR pile-up. The infrastructure equivalents map almost one to one.
Port conflicts become stack-name collisions. Two agents naming their stack dev and racing each other into Pulumi Cloud. The fix is the same hash-the-path trick the app-code playbook uses: derive the stack name from pulumi.getProject() plus a hash of the worktree path. Resource names follow the same pattern. Collisions go away.
node_modules sprawl becomes provider plugin sprawl, mostly already solved. Three worktrees each pulling their own copy of pulumi-aws would add up fast, except Pulumi already shares plugins through a single cache at ~/.pulumi/plugins. Identical provider versions are reused across worktrees automatically. Per-worktree language SDKs (node_modules, venv) still need the usual care, but the provider layer is free.
Database conflicts become state conflicts. Two agents racing each other into pulumi up on the same stack is the same hazard as two agents writing to the same migrated database. The app-code playbook reaches for Neon branches or per-worktree SQLite files to isolate state. The infra answer is simpler: each worktree gets its own review stack. State branches with the work, by construction.
Token blowouts become cloud spend per ephemeral stack. The cost vector flips. For app code, the worry is LLM bills. For infrastructure, the worry is what your five agents just spun up in five review stacks. The mitigations are boring and they work. Use TTL stacks to tear review stacks down on a schedule. Avoid retainOnDelete on review-stack resources so the teardown actually frees them. Cap retries per spec. Watch the bill.
PR pile-up is the same problem. Five reviewed diffs are still five things waiting on the merge queue. The infra-flavored mitigations: stack-scoped reviewers (the human who owns the stack approves the change to it), the Pulumi Cloud audit log for grouping by stack and time, and auto-merge for the narrow class of changes where the preview diff is clean and every policy passes. That last one is where most of the throughput hides.
Run any agent on your stacks
Where to start, this afternoon
Three steps, in order, on a stack with a small blast radius.
- Write an
AGENTS.mdfor the repo. Five paragraphs is enough. The component library, the stack naming convention, the policy rules, the review-stack TTL, and the one thing in this repo that bites every newcomer. Neo readsAGENTS.mdnatively, as do most coding agents. This file is the spec for how the agent should behave even before you write a spec for what it should build. - Cut a 24-hour review-stack TTL. Spin up a review stack on PR open, tear it down on PR close or after 24 hours, whichever comes first. This is the gate that turns “ephemeral” from a slogan into a line item that does not appear on next month’s bill.
- Run three issues in parallel. Pick three open issues that touch unrelated resources. Spin up three worktrees, three review stacks, three ESC environments. Let each agent run end-to-end against its own stack. Then have a fourth agent read each preview JSON cold and produce a one-paragraph review. Read three PRs plus the reviewer’s summary at lunch.
That last step is the measurement. The first time you run it, half of the changes will fail validation. The second time, fewer. By the third time you will know whether your spec quality, your policies, and your stack hygiene are good enough to scale this to five, then ten, then to every issue tagged infra:fix.
If three issues finish cleanly, you have the substrate. If they do not, the gap is almost always in the spec or the policy rules, not the agent. Fix the spec, tighten the rule, run it again.
Five stacks before lunch
10x is five concurrent agents, working from five issues, against five stacks, behind five fresh-session reviews. The substrate is already there. Stacks isolate state. ESC isolates credentials. pulumi preview is the deterministic artifact a fresh reviewer can read cold. Pulumi Policies is the self-healing layer when you write the rule messages as instructions.
The remaining work is small and mostly wiring. Write the AGENTS.md. Cut the TTL. Pick three issues that touch unrelated resources. Read three PRs at lunch. Five stacks before the room empties out is a realistic Monday.



{kind=link}