{kind=link}
Executive summary
Fauna, the data API for modern applications, was preparing to launch a major new feature that would allow its customers to meet local data residency requirements with all the benefits of distributed, serverless databases. With a short timeline and small team, Fauna’s developers needed a universal infrastructure-as-code solution that would support the project’s complex requirements, including multi-cloud and multi-region support. They also wanted to increase their velocity by using software engineering practices with infrastructure. By using the Pulumi Cloud Engineering Platform, Fauna shortened its time-to-market from weeks to days because its developers could build, deploy, and manage multi-cloud applications faster than before using their language of choice, Python. Pulumi also allowed them to apply software engineering practices to infrastructure, which increased developer productivity and infrastructure reliability.
Building the data API for modern applications using modern infrastructure practices
About Fauna
Fauna is a flexible, developer-friendly, transactional database delivered as a secure and scalable cloud API with native GraphQL. With Fauna, you simply create a database and never have to worry about database operations. Fauna handles it all—provisioning, scaling, sharding, replication and correctness. With Fauna, developers can simplify code, reduce costs, and ship faster by replacing their entire database infrastructure with a highly productive, programmable, yet operations-free data API. Some Fauna customers include innovators such as DIGITALAX, Hannon Hill, EIDU, MJH Life Sciences, MeetKai, Delicious Simplicity, and Matter Supply Co.
Designing for data residency
In 2021, Fauna was preparing to launch a significant new feature, called Region Groups, that would allow its customers to store their data in a specific geography, with all the benefits of Fauna’s serverless, low-latency, and high availability database. Region Groups was important because it would enable Fauna’s customers to meet legal or regulatory requirements governing sensitive data, such as General Data Protection Regulation (GDPR) and Federal Information Processing Standards (FIPS). As a serverless database, Fauna would manage the database operations on behalf of its customers, including data distribution and scaling database resources.
Finding the right platform
The benefits of Region Groups were simple, but building the feature would be complex and demanding. In addition to maintaining Fauna’s core benefits of high availability and responsive scaling, Fauna’s engineers needed a way to fulfill several key requirements:
- Dynamically coordinate cloud services on multiple cloud platforms and across different geographic regions.
- Minimize the blast radius of errors in order to maintain high operational standards for availability and reliability.
- Secure access to cloud infrastructure and sensitive data using security best practices.
Fauna’s engineers needed a modern, cloud engineering solution that would meet the sophisticated technical demands of the project. Legacy Infrastructure as Code tools would not be sufficient because they lacked the programmability needed to orchestrate complex multi-cloud deployments and workflows. In addition, their domain specific languages (DSLs) were cumbersome, difficult to use, and incompatible with modern software engineering.
Why Pulumi?
Fauna chose Pulumi because it would allow its developers to adopt modern, cloud engineering practices out-of-the-box and increase velocity. With Pulumi, developers can build infrastructure as code with standard languages they already know, such as Python, TypeScript/JavaScript, Go, and C#. They can deploy infrastructure changes through existing CI/CD pipelines, just like application code. Finally, they can manage cloud infrastructure and applications with full visibility into every resource, access controls, and Policy as Code.
How Fauna built region groups with Pulumi
Building modern applications that are multi-cloud and multi-region
Fauna runs its database service on multiple clouds, including AWS and Google Cloud. With the Region Groups feature, Fauna creates and manages database clusters that are multi-region and consist of VPCs, subnets, VMs, and load balancers. In addition, Fauna needed to make sure the clusters could auto-scale and it needed the ability to spin up new clusters in a Region Group based on demand in a few hours.
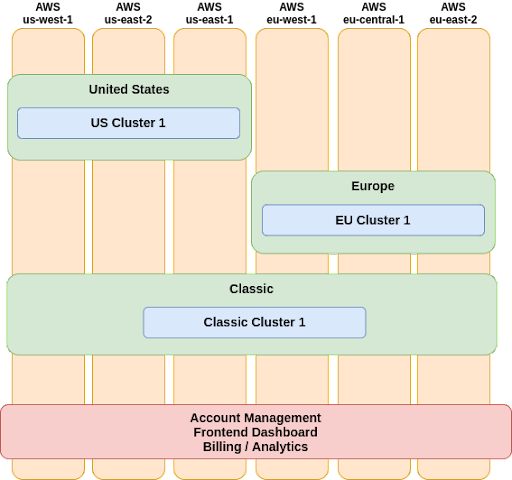
With Pulumi, Fauna’s developers could build, deploy, and manage infrastructure as code across multiple clouds using Python, their language of choice. They could use programming concepts and tools that they were already familiar with, such as object-oriented programming, reusability, IDEs, and standard Python libraries. This gave them the flexibility to model complex infrastructure with the full expressivity of modern languages, and share and reuse it like any software code.
Improving infrastructure reliability in spite of increased complexity
The second goal was to ensure that any incorrect changes would impact the fewest number of customers possible. Pulumi helped them achieve this in several ways.
Pulumi allowed Fauna’s developers to organize their infrastructure code into logical groupings that simplified making changes and reduced the blast radius of bugs. Using Pulumi projects and stacks, the developers modeled their infrastructure as layers represented by four projects (Accounts, Networks, Replicas, and Proxies), with each project containing Pulumi stacks that represent database replicas. The stacks can be dynamically coordinated by passing output values to each other, such as account IDs or subnet IDs. The developers chose this strategy because it would reduce the number of resources potentially affected by any change, thereby minimizing the impact of any bugs.
In addition, Pulumi enabled the developers to use tried and true software engineering practices that increased reliability and reduced errors. For example, they could version control the code, run unit tests against code, and vet changes through their code review process.
Securing access to infrastructure and its sensitive data
Fauna used Pulumi’s security and access control capabilities to maintain the security of its infrastructure. It manages user access using Pulumi’s single sign-on (SSO) integration with its identity provider. Using Pulumi’s role-based access controls, it can define who has access to which stacks.
Fauna could also easily integrate its secrets manager tool, HashiCorp Vault, with Pulumi. Although Pulumi provides built-in secrets management, Fauna decided to use its existing secrets manager to encrypt sensitive configuration values such as credentials.
Future plans
Fauna is using Pulumi’s Automation API to manage its quality assurance clusters and plans to extend its use in production clusters to further automate its infrastructure deployment process by running changes through a CI/CD pipeline. Automation API enables Fauna to use the Pulumi engine as an SDK and build applications that dynamically manage infrastructure. Fauna also plans to adopt Pulumi’s AWS Cloud Control Provider, which provides 100% coverage of resources in the AWS Cloud Control API and has same-day access to new AWS launches.
How Pulumi benefits Fauna
Pulumi enabled Fauna to develop a crucial new feature, Region Groups, by giving developers the capabilities they needed to build and deploy quickly and safely. The benefits were:
- Reduced time-to-market from weeks to days in spite of a small team because developers could build infrastructure as code with standard languages (Python, TypeScript, Go, C#).
- Increased velocity because developers were more productive building cloud applications with software engineering practices and tools they were already using.
- Improved the reliability of infrastructure because developers could use safety mechanisms such as unit tests and code reviews against changes.
- Maintained the security of infrastructure that handled customer data using Pulumi’s security, encryption, and access control features.
- Improved the quality of the Fauna service because developers can rapidly deploy and test pre-production environments that are similar to production, using the same infrastructure tooling.
To learn more about how Fauna used Pulumi to develop its serverless database, read the technical deep-dive blog, Building Fauna’s GDPR-compliant distributed and scalable database infrastructure with Pulumi.