
Serverless architectures have gained and continue to gain significant traction in modern application development. Despite its name, serverless doesn’t mean servers are absent; instead, it represents a paradigm shift in how applications are built, deployed, and scaled in the cloud.
What is serverless?
Serverless refers to a cloud computing execution model where cloud providers manage the infrastructure automatically, abstracting away the complexity of server management from developers. In a serverless architecture, developers focus solely on writing code for individual functions or services without concerning themselves with server provisioning, scaling, or maintenance.
How does serverless relate to functions-as-a-service (FaaS)?
The term functions as a service (typically abbreviated as FaaS) focuses specifically on the serverless execution of functions in response to events. FaaS is a subset of serverless, emphasizing the granular, event-driven nature of the architecture. Serverless, on the other hand, encompasses the entire architecture, including FaaS. It emphasizes the abstracted, managed nature of the infrastructure.
Some FaaS platforms used in serverless architectures include:
What is an event-driven architecture, and is it different than serverless?
Event-driven architecture describes the broader architectural pattern where different components of an application respond to events. These events can be distributed among application components using mechanisms like message queues, publish-subscribe services, or event buses. Serverless architectures are event-driven architectures. While often associated with serverless, event-driven architectures can exist independently, involving both serverless and traditional infrastructure. In other words, while all serverless architectures are event-driven architectures, not all event-driven architectures are serverless architectures.
What are some of the benefits of serverless?
Adopting a serverless architecture can offer a number of benefits:
- Cost-efficiency: With serverless, you pay only for the computing resources used during the execution of functions, making it a cost-effective solution, especially for sporadically used applications.
- Autoscaling: Serverless platforms automatically scale based on demand, ensuring optimal resource utilization without the need for manual intervention.
- Reduced operational overhead: Developers can focus on writing code and building features instead of managing servers, leading to increased productivity and faster time-to-market.
- Facilitates a microservices architecture: Serverless facilitates the development of microservices, allowing developers to break down applications into smaller, manageable components that can be individually developed, deployed, and scaled.
What are some considerations for designing my serverless application?
Use well-defined and focused functions: A serverless function should have a well-defined purpose and focus on a specific task. If a function has multiple responsibilities, consider breaking it into smaller, more focused functions. In the code shown below, we have two functions
dateandweatherand it is clear what their responsibilities are.// The 'date' function that returns the current date mux.HandleFunc("/api/date", func(w http.ResponseWriter, r *http.Request) { w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") if r.Method == http.MethodOptions { w.WriteHeader(http.StatusNoContent) return } w.Header().Set("Content-Type", "application/json") w.Write([]byte(fmt.Sprintf(`{ "now": %d }`, time.Now().UnixNano()/1000000))) }) // The 'weather' function that returns the weather mux.HandleFunc("/api/weather", func(w http.ResponseWriter, r *http.Request) { w.Header().Set("Access-Control-Allow-Origin", "*") w.Header().Set("Access-Control-Allow-Methods", "GET") if r.Method == http.MethodOptions { w.WriteHeader(http.StatusNoContent) return } weather := getWeatherData() // Convert the weather data to JSON. responseJSON, err := json.Marshal(weather) if err != nil { http.Error(w, "Error encoding response to JSON", http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json") w.WriteHeader(http.StatusOK) w.Write(responseJSON) })Embrace statelessness: Serverless functions should be stateless. This encourages scalability and fault tolerance since every serverless function call should be able to function on its own, regardless of previous or subsequent calls. The recommended practice for managing data that has to be persistent beyond the span of one function execution is to store it externally in reliable data storage systems like object stores or databases:
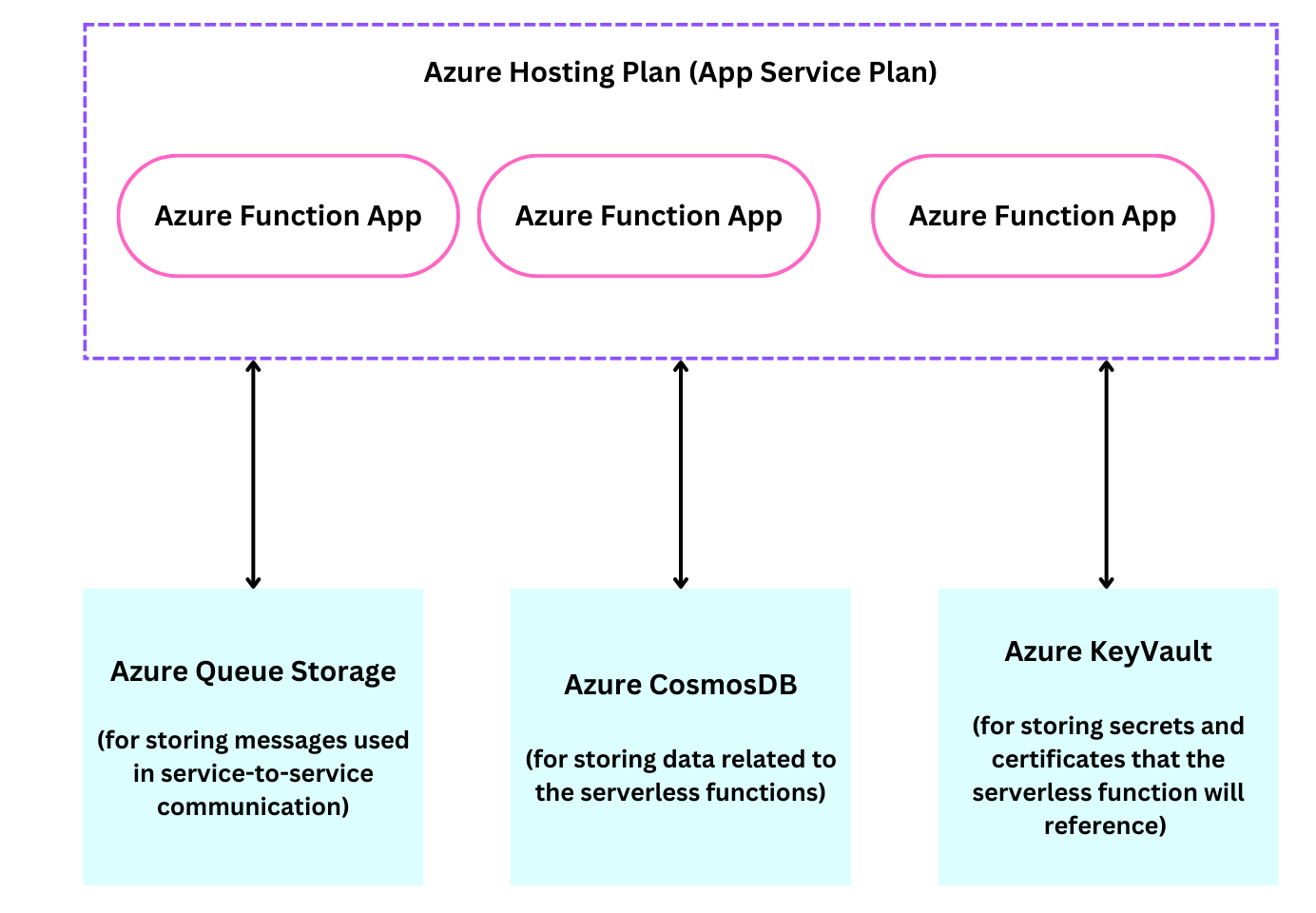
In doing so, serverless applications maintain the clear separation between function logic and stateful data management while guaranteeing data durability, consistency, and adaptability to changing workloads. The stateless nature of HTTP is an important aspect that makes serverless computing a good fit for many HTTP-based use cases. In a stateless protocol like HTTP, each request from a client to a server is treated independently, with no connection or context maintained between requests. This aligns well with the design philosophy of serverless computing, where each function execution is isolated and stateless.
Choose the right trigger: When dealing with serverless functions you should choose the trigger that best suits your use case. Common triggers include HTTP requests, message queues, database changes, and timers. In our application, we used an HTTP trigger for our two functions.
// The 'date' function that returns the current date mux.HandleFunc("/api/date", func(w http.ResponseWriter, r *http.Request) { ... }) // The 'weather' function that returns the weather mux.HandleFunc("/api/weather", func(w http.ResponseWriter, r *http.Request) { ... })Avoid making direct cross-service references: In your serverless architecture, there are times when functions depend on other functions. This typically happens a lot in distributed systems. For example in an e-commerce service, the checkout function could depend on the payment function. However, it’s advised that services avoid making direct references to one another in order to prevent hard coupling that can cause issues later. A significant amount of reworking may be required if direct references for a service need to be changed. Using message services, such as queues or topics, to facilitate service-to-service communication is a good way to handle this. This decoupling enhances flexibility, scalability, and resilience, as well as simplifies testing and debugging. It also promotes security by allowing access control. When you use a more decoupled architecture, serverless systems can evolve independently and adapt to changing requirements, making them more robust and maintainable over time.
Conclusion
Serverless architectures empower developers to build scalable, cost-effective applications without the burden of managing servers. By understanding its components, associated cloud services, and benefits, technical professionals can leverage serverless to streamline development processes and create more agile, responsive applications in the cloud.
Pulumi’s code-driven approach to infrastructure as code aligns well with serverless architectures, allowing developers to use the same tools for writing their serverless functions and their infrastructure definitions. This set of Pulumi architecture templates make it easy to deploy a serverless application using Pulumi—check it out!
Our community on Slack is always open for discussions, questions, and sharing experiences. Join us there to share your experience with using Pulumi for serverless applications, or to ask questions about how Pulumi can streamline your serverless application deployments. Become part of our growing community of cloud professionals!
Get started today
Get started today
Pulumi is open source and free to get started. Deploy your first stack today.
Get started