Getting Started With Kubernetes: Application Basics

Welcome to the second article in a series using infrastructure as code to deploy applications with Kubernetes. The series walks you through building a Kubernetes cluster on cloud providers, deploying applications, and “Day 2” activities such as migrating Node groups. In the previous article, we showed how to create a Kubernetes cluster for AWS, Azure, and GCP. In this installment, we’ll learn how to deploy an application using Kubernetes objects.
Kubernetes has a rich feature set and it is important to keep in mind that Kubernetes is not merely a container orchestrator. It is designed to keep applications highly available and to scale on demand. It accomplishes this by running multiple instances of application containers and replacing them as needed.
There are many moving parts to Kubernetes, so let’s review the objects used to deploy applications in Kubernetes.
Pods
A Pod is where applications run, and it is the smallest unit of execution for Kubernetes. A Pod hosts one or more containers that make up a complete application. For example, a Pod can have a container running an entire LAMP stack for a web application, or it can run a container with NGINX that connects to a database running in another Pod.
Each Pod has an IP address and can address other Pods in the same network. In the previous article, we deployed clusters in a VPC. Pods deployed in a Kubernetes cluster can communicate with each other using TCP/IP, UDP, or SCTP. Containers within a Pod share the same IP address and port space, and can communicate via localhost or IPC, such as POSIX shared memory or SystemV semaphores.
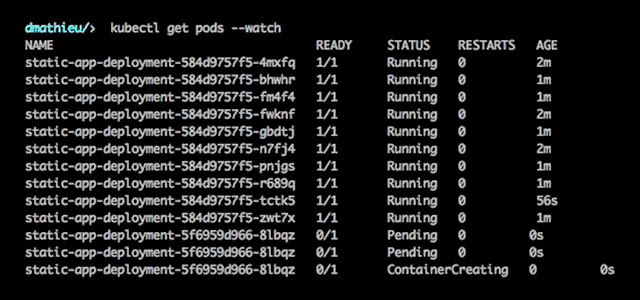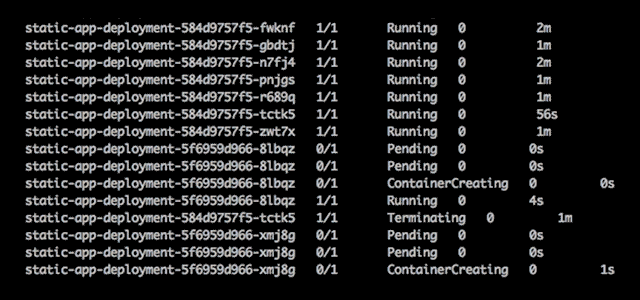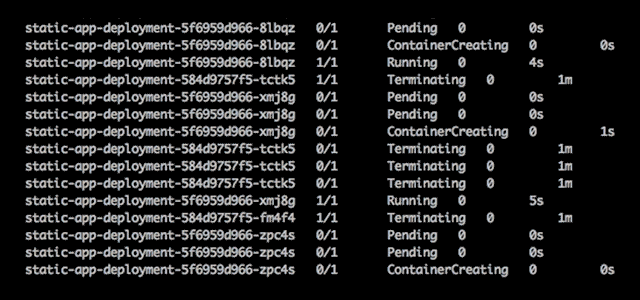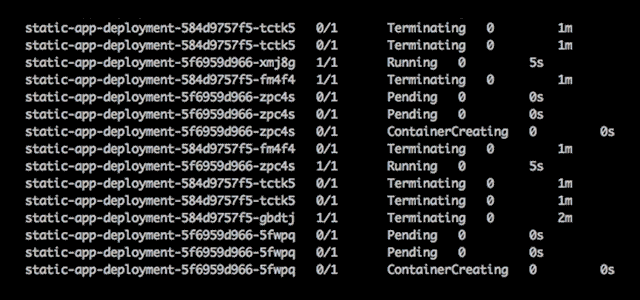
Pods have a specific lifecycle. They are created, assigned a UID, scheduled to run on a Node, and run until they either fail or are terminated. When a Node dies, Pods are deleted and replaced onto other nodes. Pods have five distinct states or phases:
- Pending The Pod has been scheduled for creation, but one or more containers have not been created.
- Running The Pod has been created in the Node, all containers have been created, and at least one container is running.
- Succeeded All the containers have been successfully terminated and will not be restarted.
- Failed All containers have been terminated, but at least one container has exited with a failed non-zero status.
- Unknown The state of the Pod was not returned, possibly due to a communication error.
When deploying an application, you can see the status of the Pods.
Services
A Service routes traffic to a logical set of Pods. For example, your application may deploy a web application, a data store for queued requests, and an RDBMS for customer data in separate Pods. A Service groups Pods using Labels and LabelSelectors. Labels are key/value pairs that you can use to identify objects meaningfully. Using the example above, the web application may be labeled tier : frontend and the database would be labeled tier : backend. Labels aren’t unique, and objects can have the same label. A LabelSelector identifies a set of objects and is a way to group objects.
Pod IPs are not exposed to traffic outside of the cluster. Applications require a Service to receive traffic, and by setting a ServiceSpec, they can be addressable by specifying a type:
- ClusterIP (default) -The Service is only addressable from within the cluster.
- NodePort - In addition to a ClusterIP, the Service is also available outside the cluster using
<NodeIP>:<NodePort>. - LoadBalancer - In addition to a Cluster IP and Node Port, the Service is also assigned a load balancer to with a fixed, external IP that routes to the Service.
- ExternalName - Uses a CNAME record to internally expose an external Service to Kubernetes within the cluster.
Volumes
Containers are ephemeral, and storage in a container is temporary as well. As soon as a container stops, any changes are lost. The lifecycle of a Kubernetes Volume is tied to a Pod, and the data in the volume is available across container restarts. If a Pod is terminated, then the data will also be lost.
Kubernetes supports many types of volumes, but of interest are PersistentVolumes, which persist beyond the lifecycle of a Pod. PersistentVolumes are a resource that has been provisioned by a Storage Class. To use a PersistentVolume, we have to declare a PersistentVolumeClaim (PVC) which allows a user to access abstract storage resources. We can declare parameters such as size, access (read/write), or volume expansion for a PVC. Applications that require a PVC are typically data stores or databases where data must be preserved outside the scope of the application in a Pod.
Namespaces
One of the advantages of Kubernetes is multi-tenancy or the ability to host many virtual clusters in the same physical cluster. Namespaces are used to organize application clusters by providing scope for names. To this end, Namespaces must be unique, cannot be nested inside another namespace, and resources can only belong to one namespace, if they are namespaced.
Namespaces are typically used where there are multiple teams or projects. For example, you may have an engineering and a marketing namespace. However, it’s more efficient to use labels if the applications are only slightly different than in grouping environments such as dev, test, and prod.
Controllers
Controllers manage the state of the cluster by making changes that move the cluster to the desired state. They watch resources making sure that objects, such as Pods, meet the spec for the declared state. The kube-controller-manager in the control plane has a built-in set of controllers. Let’s take a look at two commonly used controllers, Deployments and ReplicaSets.
A Deployment is a higher-level object that manages declarative updates for Pods and ReplicaSets. But first, let’s look at ReplicaSets, which are a set of Pods running the same application at any given time. As such, it is often used to guarantee the availability of a specified number of identical Pods. A ReplicaSet creates and deletes Pods as needed to meet the criteria of the declared state, and uses Labels and Selectors to determine which Pods to manage.
A Deployment is a higher-level abstraction that manages ReplicaSets by updating Pods. Deployments are commonly used instead of directly using ReplicaSets because the Deployment controller manages updates to the desired state at a controlled rate. For example, you can specify a rolling update to limit the downtime of an application.
Examples
Now that we have the basic Kubernetes objects, let’s see how they are used in a Kubernetes deployment across cloud providers.
In this example, we’ll deploy Nginx. We’ll skip the cluster creation, which we covered in the previous installment. We set name to helloworld and use it to set the Namespace for the application and the Label (appLabel). The Deployment uses these parameters in the metadata section.
The spec section of a Deployment specifies the desired state; in this example, we want one Replica, and the selector must match appLabel. The Deployment spec includes the application container and claims port 80 on the Pod. To make our deployment available outside the cluster, we create a LoadBalancer service that routes requests to the container. As with the Deployment, we add the Labels and Namespace to the metadata. The Service spec sets the type to LoadBalance and opens port 80 externally. Note that the selector uses appLabels to acquire the Pods from our Deployment.
...
const name = "helloworld";
// Create a Kubernetes Namespace
const ns = new k8s.core.v1.Namespace(name, {}, { provider: cluster.provider });
// Export the Namespace name
export const namespaceName = ns.metadata.name;
// Create a NGINX Deployment
const appLabels = { appClass: name };
const deployment = new k8s.apps.v1.Deployment(name,
{
metadata: {
namespace: namespaceName,
labels: appLabels,
},
spec: {
replicas: 1,
selector: { matchLabels: appLabels },
template: {
metadata: {
labels: appLabels,
},
spec: {
containers: [
{
name: name,
image: "nginx:latest",
ports: [{ name: "http", containerPort: 80 }],
},
],
},
},
},
},
{
provider: cluster.provider,
},
);
// Export the Deployment name
export const deploymentName = deployment.metadata.name;
// Create a LoadBalancer Service for the NGINX Deployment
const service = new k8s.core.v1.Service(name,
{
metadata: {
labels: appLabels,
namespace: namespaceName,
},
spec: {
type: "LoadBalancer",
ports: [{ port: 80, targetPort: "http" }],
selector: appLabels,
},
},
{
provider: cluster.provider,
},
);
// Export the Service name and public LoadBalancer Endpoint
export const serviceName = service.metadata.name;
export const serviceHostname = service.status.loadBalancer.ingress[0].hostname;
We can compare this deployment to a YAML manifest that accomplishes the same thing. The YAML deployment is similar to the one above written in code. A manifest for the service is also required to deploy the application. You can use kubectl to apply the manifests.
apiVersion: apps/v1
kind: Deployment
metadata:
Labels:
namespace: helloworld
labels: appLabels
spec:
replicas: 1
selector:
matchLabels: appLabels
template:
metadata:
labels: appLabels
spec:
containers:
- name: helloworld
image: nginx:latest
ports:
- containerPort: 80
Although this is a simple example, you can see where using a programming language has advantages over editing YAML files, e.g., you can edit the name, namespace, and labels just once. The full example is available on GitHub for you to try.
In this example, we’ll deploy Nginx. We’ll skip the cluster creation which we covered in the previous installment. We set name to helloworld and use it to set the Namespace for the application and the Label (appLabel). The Deployment uses these parameters in the metadata section.
The spec section of a Deployment specifies the desired state; in this example, we want one Replica, and the selector must match the appLabel. The Deployment spec includes the application container and claims port:80 on the Pod. To make our deployment available outside the cluster, we create a LoadBalancer service that routes requests to the container. As with the Deployment, we add the Labels and Namespace to the metadata. The Service spec sets the type to LoadBalance and opens port 80 externally. Note that the selector uses appLabels to acquire the Pods from our Deployment.
...
const name = "helloworld";
// Create a Kubernetes Namespace
const ns = new k8s.core.v1.Namespace(name, {}, { provider: cluster.provider });
// Export the Namespace name
export const namespaceName = ns.metadata.name;
const deployment = new k8s.apps.v1.Deployment(name,
{
metadata: {
namespace: namespaceName,
labels: appLabels,
},
spec: {
replicas: 1,
selector: { matchLabels: appLabels },
template: {
metadata: {
labels: appLabels,
},
spec: {
containers: [
{
name: name,
image: "nginx:latest",
ports: [{ name: "http", containerPort: 80 }],
},
],
},
},
},
},
{
provider: cluster.provider,
},
);
// Export the Deployment name
export const deploymentName = deployment.metadata.name;
// Create nginx service
const service = new k8s.core.v1.Service(name,
{
metadata: {
labels: appLabels,
namespace: namespaceName,
},
spec: {
type: "LoadBalancer",
ports: [{ port: 80, targetPort: "http" }],
selector: appLabels,
},
},
{
provider: cluster.provider,
},
);
// Export the Service name and public LoadBalancer Endpoint
export const serviceName = service.metadata.name;
export const serviceHostname = service.status.loadBalancer.ingress[0].ip;
We can compare this deployment to a YAML manifest that accomplishes the same thing. The YAML deployment is similar to the one above written in code. A manifest for the service is also required to deploy the application. You can use kubectl to apply the manifests.
apiVersion: apps/v1
kind: Deployment
metadata:
Labels:
namespace: helloworld
labels: appLabels
spec:
replicas: 1
selector:
matchLabels: appLabels
template:
metadata:
labels: appLabels
spec:
containers:
- name: helloworld
image: nginx:latest
ports:
- containerPort: 80
Although this is a simple example, you can see where using a programming language has advantages over editing YAML files, e.g., you can edit the name, namespace, and labels just once.
In this example, we’ll deploy Nginx. We’ll skip the cluster creation, which we covered in the previous installment. We set name to helloworld and use it to set the Namespace for the application and the Label (appLabel). The Deployment uses these parameters in the metadata section.
The spec section of a Deployment specifies the desired state; in this example, we want one Replica and the selector must match the appLabel. The Deployment spec includes the application container and claims port:80 on the Pod. To make our deployment available outside the cluster, we create a LoadBalancer service that routes requests to the container. As with the Deployment, we add the Labels and Namespace to the metadata. The Service spec sets the type to LoadBalance and opens port 80 externally. Note that the selector uses appLabels to acquire the Pods from our Deployment.
...
const name = "helloworld";
// Create a Kubernetes Namespace
const ns = new k8s.core.v1.Namespace(name, {}, { provider: clusterProvider });
// Export the Namespace name
export const namespaceName = ns.metadata.name;
// Create a NGINX Deployment
const appLabels = { appClass: name };
const deployment = new k8s.apps.v1.Deployment(name,
{
metadata: {
namespace: namespaceName,
labels: appLabels,
},
spec: {
replicas: 1,
selector: { matchLabels: appLabels },
template: {
metadata: {
labels: appLabels,
},
spec: {
containers: [
{
name: name,
image: "nginx:latest",
ports: [{ name: "http", containerPort: 80 }],
},
],
},
},
},
},
{
provider: clusterProvider,
},
);
// Export the Deployment name
export const deploymentName = deployment.metadata.name;
// Create a LoadBalancer Service for the NGINX Deployment
const service = new k8s.core.v1.Service(name,
{
metadata: {
labels: appLabels,
namespace: namespaceName,
},
spec: {
type: "LoadBalancer",
ports: [{ port: 80, targetPort: "http" }],
selector: appLabels,
},
},
{
provider: clusterProvider,
},
);
// Export the Service name and public LoadBalancer endpoint
export const serviceName = service.metadata.name;
export const servicePublicIP = service.status.loadBalancer.ingress[0].ip;
We can compare this deployment to a YAML manifest that accomplishes the same thing. The YAML deployment is similar to the one above written in code. A manifest for the service is also required to deploy the application. You can use kubectl to apply the manifests.
apiVersion: apps/v1
kind: Deployment
metadata:
Labels:
namespace: helloworld
labels: appLabels
spec:
replicas: 1
selector:
matchLabels: appLabels
template:
metadata:
labels: appLabels
spec:
containers:
- name: helloworld
image: nginx:latest
ports:
- containerPort: 80
Although this is a simple example, you can see where using a programming language has advantages over editing YAML files, e.g., you can edit the name, namespace, and labels just once. The full example is available on GitHub for you to try.
Conclusion
This article reviews the Kubernetes objects and abstractions used to deploy applications. Deploying an application using Pulumi’s infrastructure as code looks similar to YAML manifests in how Deployments and Services are configured. The advantage of using a programming language to deploy an application is that you have the full range of software development tools available to you, such as defining variables, code completion, error checking, and versioning. In contrast, maintaining a set of YAML manifests can be an error-prone exercise in copying and pasting.
This is the second in a series of articles on using infrastructure as code for Kubernetes. In the next article, we’ll examine a complex application deployment and a deployment using a Helm chart. Until the next post, learn more about Kubernetes with these resources.
- Watch educational content on Pulumi TV
- Learn more about Pulumi’s support for Kubernetes
- Practice Kubernetes Tutorials using Pulumi