Pulumi's Declarative and Imperative Approach to IaC

{kind=link}
On a regular basis, articles and tweets pass by discussing whether some specific tool is imperative or declarative.
It’s no surprise that Pulumi is often the tool being debated. What if I tell you that Pulumi is imperative, declarative and imperative?
When we look at our Frequently Asked Questions, we read the following on the declarative versus imperative topic:
Pulumi is a declarative tool that uses imperative languages to define your end state. The language is used for authoring your program. It’s not used for talking to the cloud provider API.
It is good to know to refresh what declarative and imperative mean:
Both terms refer to how the user provides direction to the automation platform. With an imperative tool, you define the steps to execute in order to reach the desired solution. With a declarative tool, you define the desired state of the final solution, and the automation platform determines how to achieve that state. (Source)
The title of the article mentions imperative and declarative both. Pulumi leverages the best of both worlds into our product.
Pulumi tries to offer a solution where our customers are only limited by their imagination rather than the tool at hand. Let me use the Pulumi architecture to highlight why I mention imperative twice.
Pulumi Architecture
Here is the diagram from our How Pulumi Works page:
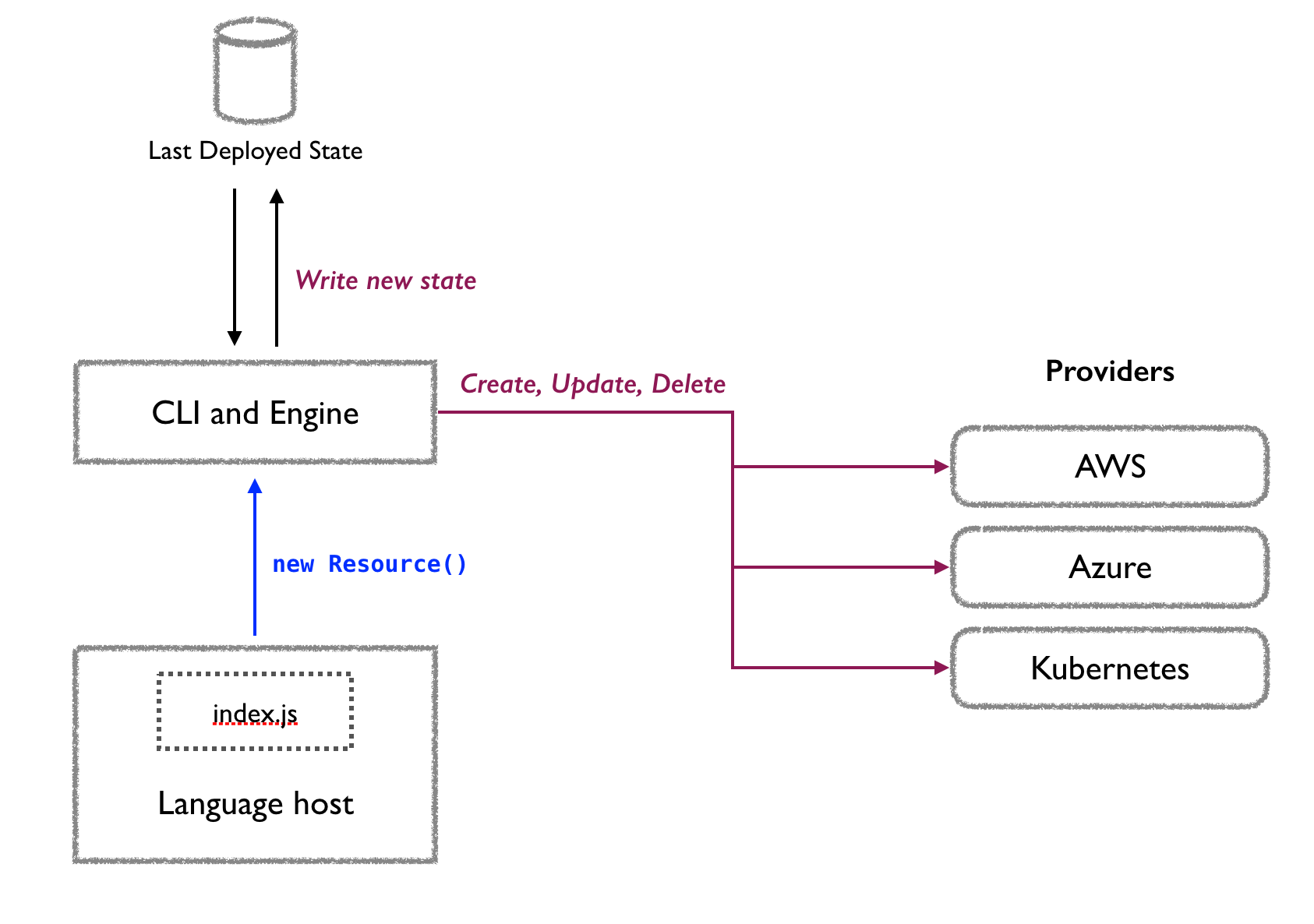
You code your infrastructure in your preferred programming language. When you are done coding, you run pulumi up and the Pulumi CLI starts the language host for your selected programming language, as well as the required providers. The interaction between these 3 parts of the architecture results in the actual creation or modification of your infrastructure.
An Imperative Part: The Language Host
Under the hood, the Pulumi CLI does a lot of things, but one of the first actions is starting the language runtime, which is configured in
the Pulumi.yaml project file:
name: blog_code
description: Example for declarative blog post
runtime: python
main: blog_code/
Once the language runtime is up, it turns to the program file. Here is a small Python example:
from pulumi_aws import s3
bucket = s3.Bucket('bucket')
for i in range(10):
s3.BucketObject(
f'object-{i}',
s3.BucketObjectArgs(
bucket=bucket.id,
key=str(i),
)
)
A Pulumi program models the to-be state of your infrastructure. If you read this program, you can find that we define 11 resources as our to-be infrastructure:
The stack itself is also modelled as a resource, and it is the parent to all other resources.
$ pulumi up
Updating (<masked>/dev)
View Live: https://app.pulumi.com/<masked>/blog_code/dev/updates/1
Type Name Status
+ pulumi:pulumi:Stack blog_code-dev created
+ ├─ aws:s3:Bucket bucket created
+ ├─ aws:s3:BucketObject object-0 created
+ ├─ aws:s3:BucketObject object-1 created
+ ├─ aws:s3:BucketObject object-3 created
+ ├─ aws:s3:BucketObject object-2 created
+ ├─ aws:s3:BucketObject object-6 created
+ ├─ aws:s3:BucketObject object-4 created
+ ├─ aws:s3:BucketObject object-5 created
+ ├─ aws:s3:BucketObject object-7 created
+ ├─ aws:s3:BucketObject object-9 created
+ └─ aws:s3:BucketObject object-8 created
Resources:
+ 12 created
Duration: 13s
While this is definitely an imperative program, there is one important thing to understand: Instantiating an s3.Bucket, s3.BucketObject, or any other Pulumi resource should not be interpreted as an imperative creation of the resource in the language host. Behind the scenes, any resource instantiation in the language host triggers a Register Resource request to the Pulumi deployment engine. All these Register Resource requests together form the resource model you as an infrastructure developer want to get in the end.
Running your program always sends the full resource model to the Pulumi deployment engine regardless of what state your current infrastructure is in.
Our previous example was shown in Python, but recently we also delivered support for YAML. The creation of our S3 bucket could be converted to this snippet:
resources:
bucket:
type: aws:s3:Bucket
The separation of language support from the engine allows us to offer both imperative & declarative solutions. But remember that none of the supported languages do any of the provisioning directly in the language host.
If the resource provisioning is not taking place in the language host, where is the magic happening then?
The Declarative Part: The CLI and Engine
In the previous step, you found out that the language host sends requests to the engine to fulfill your to-be infrastructure.
It is now that the Pulumi deployment engine gets to work. The engine combines the intended model of the infrastructure received from the language host, the current state recorded in the state backend, and the actual resource state to compute which actions need to be executed to bring the actual state in line with the intended model.
Our little example contains dependencies: every s3.BucketObject uses the bucket.id as a way to define in which bucket these objects should be stored. The property id from the s3.Bucket is an Output. Outputs are Pulumi’s way of tracking which property of one resource is required by another, hereby creating a dependency between the resources. The engine uses all these outputs passed from one resource to another as the vertices in a directed acyclic graph (DAG). The engine determines the order of actions based on this graph.
On a first run of pulumi up of our example program, the engine will first create the bucket and wait for the provisioning to be complete, after which the actual bucket ID is passed to the creation of all the bucket objects. Since none of the bucket objects depend on other resources, these bucket objects can all be provisioned concurrently.
On a second run, assuming no modifications to our example program, the Pulumi deployment engine will compare the to-be model with the actual state and conclude that nothing needs to be done.
Let’s crank up the number of bucket objects to 11.
from pulumi_aws import s3
bucket = s3.Bucket('bucket')
for i in range(11): # <- number of objects increased by 1
s3.BucketObject(
f'object-{i}',
s3.BucketObjectArgs(
bucket=bucket.id,
key=str(i),
)
)
The third Pulumi run will find the bucket and the first 10 objects in the state. The only action taken now is the creation of the 11th bucket object. This brings the actual state back in sync with your intended model.
$ pulumi up
Updating (<masked>/dev)
View Live: https://app.pulumi.com/<masked>/blog_code/dev/updates/2
Type Name Status
pulumi:pulumi:Stack blog_code-dev
+ └─ aws:s3:BucketObject object-10 created
Resources:
+ 1 created
12 unchanged
Duration: 5s
Although you create the intended model of your infrastructure with an imperative language, the engine definitely processes this in a declarative way.
Another Imperative Part: The Providers
These examples hopefully made clear that the Pulumi deployment engine calculates a set of actions to declaratively bring the actual state in sync with your intended model. But the engine is not the component which knows how to talk to all the different APIs of cloud and tool vendors. That’s the role of the provider.
The engine and the provider processes are connected with a gRPC connection. This is similar to the connection between the language host and the engine, with the only difference of which requests are sent. The API that providers expose are of a CRUD nature:
- Create: create a new resource
- Read: read information of an existing resource
- Update: update an existing resource with modified information
- Delete: delete an existing resource when no longer needed
The providers receive requests from the engine dependent on the set of actions the engine calculated. A provider doesn’t know anything about the state, the correlation between resource, and so forth.
The nature of the provider API is clearly imperative.
Summary
If the question ever pops up again whether Pulumi is declarative or imperative, the answer is clearly we are both. It is only based on which component of our architecture you are talking about:
- Language host: imperative (JS/TS, Go, Python, C#/F#/.NET, Java) and declarative (YAML)
- Pulumi engine: declarative
- Providers: imperative
To us, it mainly matters if we can solve your infrastructure automation problem. If you still miss something in our offering, we want to hear from you!