Developer Portal Gallery: Org Templates, Pulumi Templates and AI Generated Templates

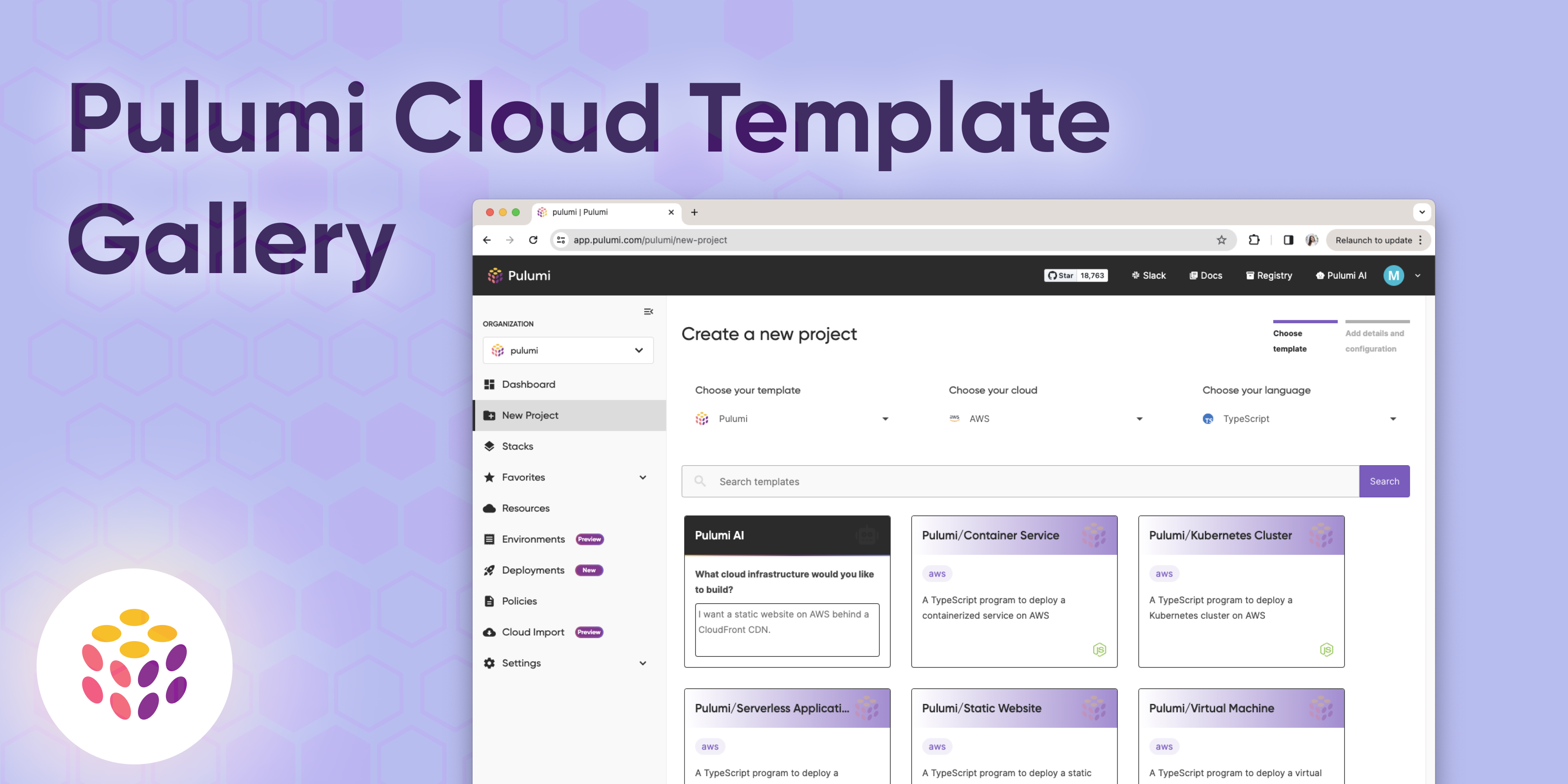
Late last year we announced Pulumi for Developer Portals: a suite of features designed to empower organizations to construct robust internal developer portals. Since launching the level of adoption and customer interest has led us to make further improvements to enhance developer productivity and collaboration in the authoring experience. We are excited to announce the latest enhancement in Pulumi Cloud: the introduction of a template gallery in New Project Wizard, making creating cloud infrastructure easier than ever.